This project takes five raw tables — transactions, cards, users, merchant-category codes, and fraud labels — and turns them into something a fraud model can actually train on. It's a standard dbt project on BigQuery, with a staging layer and a marts layer. The interesting part is the feature store at the end, and one rule it has to obey.
The shape: staging → marts
Nothing exotic in the layering, on purpose. Staging models are views that rename, cast and lightly clean each source — parse dates, trim merchant fields, normalise error values, add a couple of derived fields like debt-to-income. The marts are tables: an enriched fct_transactions fact (incremental, so it only processes new rows), a dim_users dimension with lifetime spend and fraud rate, a daily rpt_fraud_summary, and the feature store.
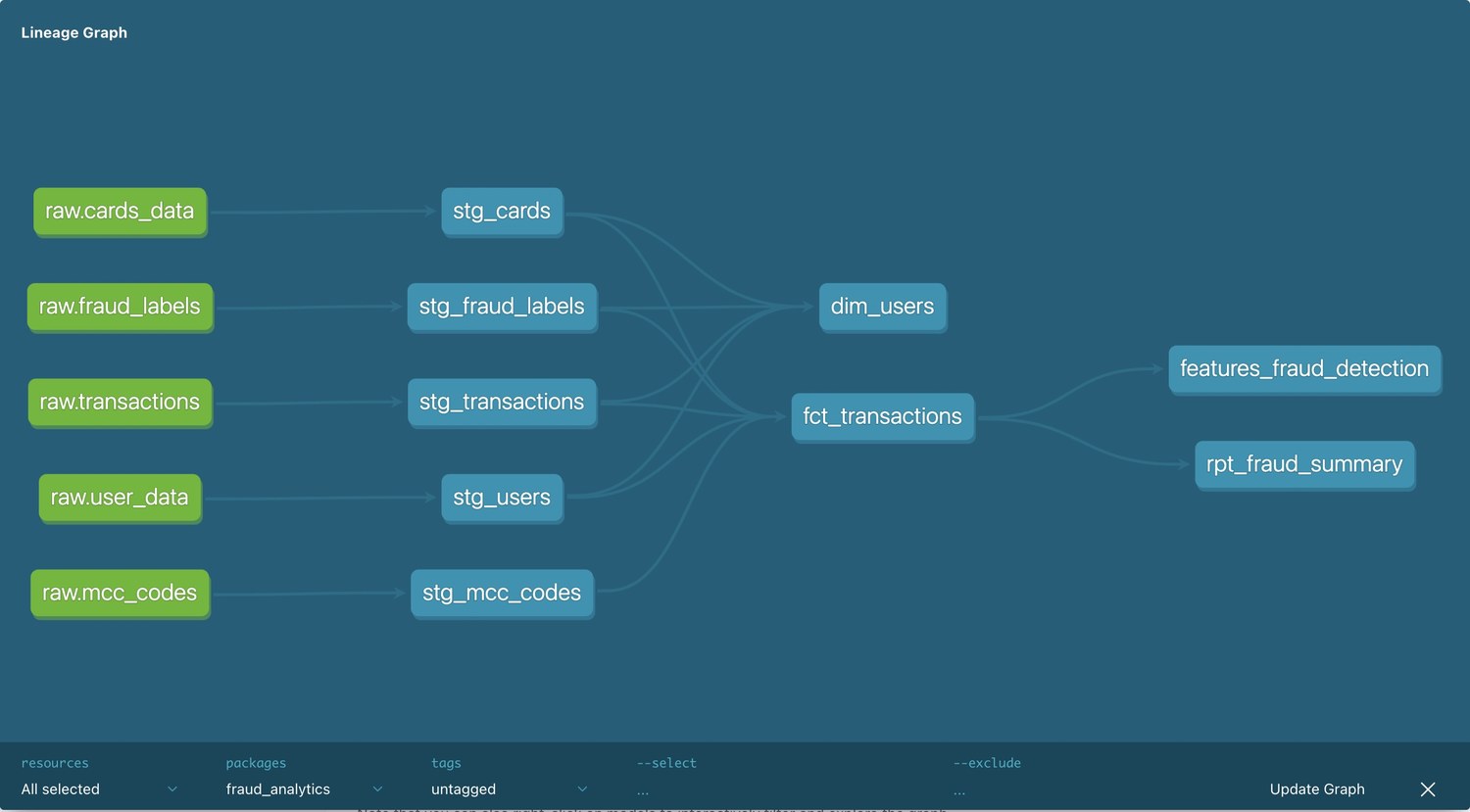
Every staging model carries tests — uniqueness and not-null on keys, and accepted_values on fields like card brand and type — so a bad assumption about the source data fails the build instead of quietly poisoning a model downstream.
The rule that matters: no leakage
Here's the part that's easy to get wrong and expensive to discover late. The feature store computes velocity, baseline and deviation features — things like "how much has this card spent in the last hour" or "how far is this amount from the user's normal." The temptation is to compute those with a plain window over the whole table.
That leaks. If a feature for a transaction includes the transaction itself — or anything after it — the model gets to peek at the future during training. It looks brilliant in evaluation and falls apart in production, because in production the future genuinely isn't available yet.
The one constraint
Every feature uses data strictly before the current transaction's timestamp — never the row itself, never anything later. Get this right once, in the transformation layer, and every model trained on the feature store inherits it for free. Get it wrong and you'll chase a phantom accuracy you can never ship.
Doing this in dbt rather than in notebook code matters: the point-in-time logic lives in one tested, versioned place that every consumer reads from, instead of being re-implemented (and re-broken) in each data scientist's feature script.
Why a fact table and a feature store, not one big query
fct_transactions is the honest record of what happened — every transaction, enriched with its dimensions and label. The feature store is a derived view of that, shaped for one purpose: training. Keeping them separate means the fact table stays reusable for reporting and analysis, while the feature store can be opinionated about leakage and time windows without distorting the source of truth.
Building clean, tested data layers that machine learning can actually trust — leakage-free, versioned, documented — is a big part of what I do at twentytwotensors. Get in touch if your feature pipeline needs that.