It's easy to ship a RAG demo that looks great on three hand-picked questions. The whole reason to evaluate is to find out where it actually breaks — so this part is about measuring the CKD assistant honestly, and being straight about what the numbers say.
How I measured it: RAGAS
I used RAGAS, which scores a RAG pipeline without a hand-labelled golden dataset by using a cheap external model as a judge. Four metrics, each answering a plain question:
- Faithfulness — did the answer only say things the retrieved text supports? (the anti-hallucination metric, and the one that matters most for anything clinical)
- Answer relevancy — did it actually address the question?
- Context precision — were the retrieved chunks actually useful?
- Context recall — did retrieval find everything it needed?
The results, unvarnished
Middling. On my retriever evaluation the aggregate landed at precision 0.53, recall 0.27, F1 0.36 — and the RAGAS faithfulness scores sat around 0.5. That is not a number I'd put on a marketing page, which is exactly why it's here.
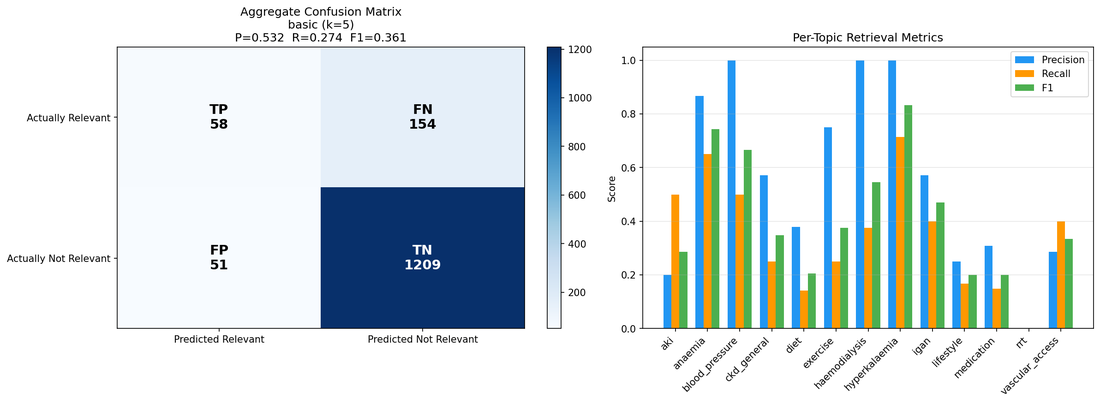
The per-topic breakdown is where it gets useful. Retrieval is decent on some topics (anaemia, hyperkalaemia) and weak on others — recall is the consistent problem: the right passage often isn't in the retrieved set at all. And if it wasn't retrieved, no amount of clever generation or extra agents can recover it.
Why it's hard, and where the fix is
This is the honest lesson of the whole series. RAG over dense clinical guidelines is genuinely difficult: the text is long, cross-referential and precise, so finding exactly the right passage — and only that — is most of the battle. Almost all the failures here were retrieval, not generation. So the next effort doesn't go into a bigger model or more agents; it goes back to the pipeline — better chunking, better recall.
What I'd take to a real build
Measure before you believe. Treat a mediocre score as the most valuable output you have — it points straight at the thing to fix. And in a high-stakes domain, a system that scores honestly and refuses when unsure beats one that scores impressively on a curated demo and quietly hallucinates in the field.
That's the series — from why three levels through the pipeline, the three levels themselves, and now the honest scorecard. Building grounded, evaluated, privacy-aware RAG — and telling you where it's weak — is what I do at twentytwotensors. Get in touch.